Python并发编程
大约 7 分钟
多进程程序例子
import argparse
import redis
from tqdm import tqdm
from multiprocessing import Pool, Process
parser = argparse.ArgumentParser(description='PyTorch MM Training')
parser.add_argument('--port', default=6379, type=str, help="port id")
parser.add_argument('--file', default=None, type=str, help="paths for train instances")
args = parser.parse_args()
host = '127.0.0.1'
port = args.port
# r = redis.Redis(host=host, port=port)
train_file = args.file
def worker_i(train_file, i, nums=16):
r = redis.Redis(host=host, port=port)
k = 0
if i == 0:
iter_ = tqdm(open(train_file, 'r'))
else:
iter_ = open(train_file, 'r')
for info in iter_:
if k % nums == i: # 将多个任务分成nums份
r.set(k, info.strip())
k += 1
process_list = []
nums = 8
for i in range(nums):
p = Process(target=worker_i, args=(train_file, i, nums))
p.start()
process_list.append(p)
for i in process_list:
p.join()
print('写入完成')
Python 中的三种并发编程方式
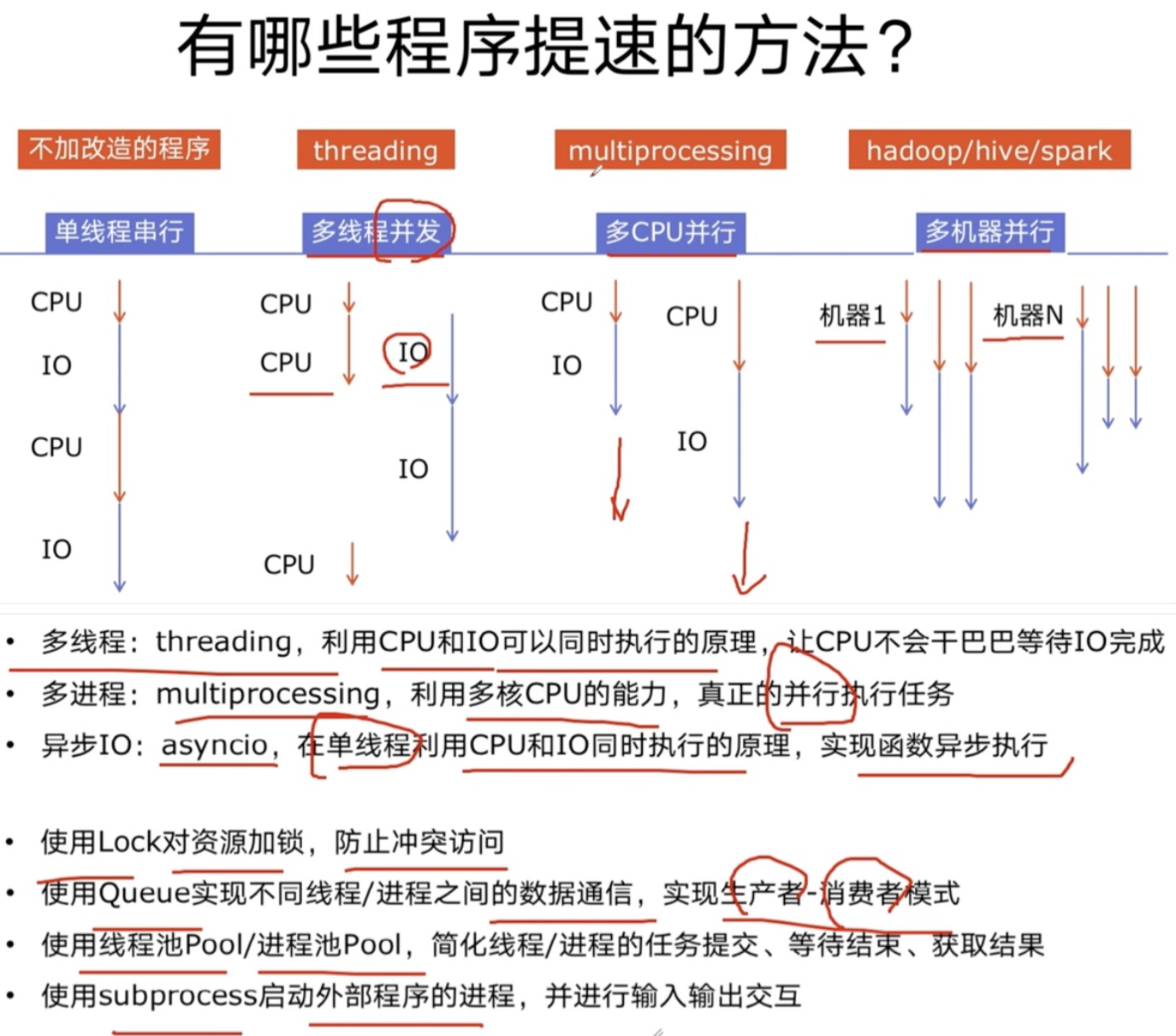
三种方式:多线程(Thread)、多进程(Process)、协程(Coroutine)
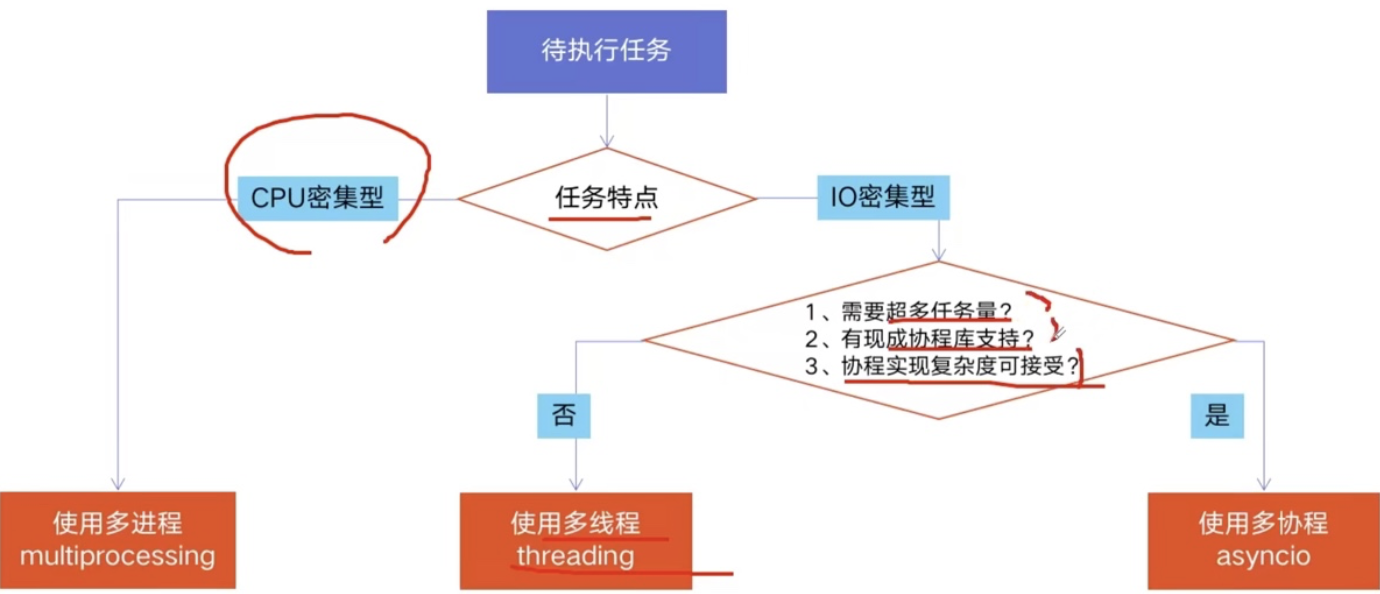
什么是 CPU 密集型计算、IO 密集型计算
- CPU 密集型计算(CPU-bound):
- 例如:压缩解压缩、加密解密
- IO 密集型计算(I/O bound):
- 爬虫、文件处理等
多线程、多进程、协程的对比
- 多进程 Process(multiprocessing)
- 优点:可以利用多核 CPU 并行运算
- 缺点:占用资源最多、可启动数目比线程少
- 适用于:CPU 密集型计算
- 多线程 Thread(threading)
- 优点:相比进程,更轻量级、占用资源少
- 缺点:
- 相比进程:多线程只能并发执行,不能利用多 CPU(GIL)
- 相比协程:启动数目有限制,占用内存资源,有线程切换开销
- 适用于:IO 密集型计算、同时允许的任务数目要求不多
- 协程 Coroutine(asyncio)
- 优点:内存开销最少、启动协程数量最多
- 缺点:支持的库有限制(aiohttp vs requests)、代码实现复杂
- 适用于:IO 密集型计算、需要超多任务运行、但有现成库支持的场景
怎样根据任务选择对应技术
全局解释器锁 GIL(Global Interpreter Lock)
Python 速度慢的两大原因:
- 动态类型语言,边解释边执行
- GIL,无法利用多核 CPU 并发执行
全局解释器锁:
- 是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。
- 即便在多核处理器上,使用 GIL 的解释器也只能允许同一时间执行一个线程。相比并发加速的 C++/JAVA 会慢很多。
- 原因详解
- 为了解决多线程之间数据完整性和状态同步问题。
- Python 中对象的管理,维护了每个对象的引用计数,在多线程时,为了保证引用计数的一致性,使用了锁的机制。
怎样规避 GIL 带来的限制:
- 那 Python 中的线程无法同时运行,为什么还要使用多线程机制呢?多线程机制在 Python 中依然是有用的,由于IO 密集型计算,因为 IO 期间,线程会释放 GIL,实现 CPU 和 IO 的并行,因此多线程用于 IO 密集型计算依然可以大幅提升速度。
- 使用 multiprocessing 的多进程机制实现并行计算、利用多核 CPU 优势。
Python 多线程代码
直接创建线程
import threading
def craw(url): # 1. 准备一个函数
r = requests.get(url)
print(len(r.text))
def multi_thread():
threads = [] # 2. 准备一个线程list
for url in urls:
threads.append( # 3. 创建线程
threading.Thread(target=craw, args=(url,))
)
for thread in threads:
thread.start() # 4. 启动线程
for thread in threads:
thread.join() # 5. 等待结束
使用线程池ThreadPoolExecutor
用法 1:使用 map 函数(所有任务一起提交)
from concurrent.futures import ThreadPoolExecutor
with ThreadPoolExecutor() as pool:
result = pool.map(craw, urls)
# map的结果和入参的顺序对应的
for result in results:
print(result)
用法 2:future 模式,更强大(一个任务一个任务提交)
from concurrent.futures import ThreadPoolExecutor, as_completed
with ThreadPoolExecutor() as pool:
# 使用 dict 可以知道future对应的入参
futures = {pool.submit(craw, url): url
for url in urls}
# 方式1: 结果仍然按顺序
for future, url in futures.items():
print(url, future.result())
# 方式2: 使用 as_completed 顺序是不定的
for future in as_completed(futures): # 注:字典的遍历是遍历key
url = futures[future]
print(url, future.result())
Python 多进程代码
多线程 threading 与多进程 multiprocessing 的代码对比

直接改个类名就能运行!
所以代码去看 Python 多线程代码
多进程优雅退出
import ctypes
import time
from multiprocessing import Process, RawValue
class CountdownTask:
def __init__(self):
self._running = RawValue(ctypes.c_bool, True)
def terminate(self):
self._running.value = False
def run(self, n):
while self._running.value and n > 0:
print('T-minus', n)
n -= 1
time.sleep(5)
c = CountdownTask()
t = Process(target=c.run, args=(10,))
t.start()
c.terminate() # Signal termination
t.join() # Wait for actual termination (if needed)
线程池原理
线程池的原理
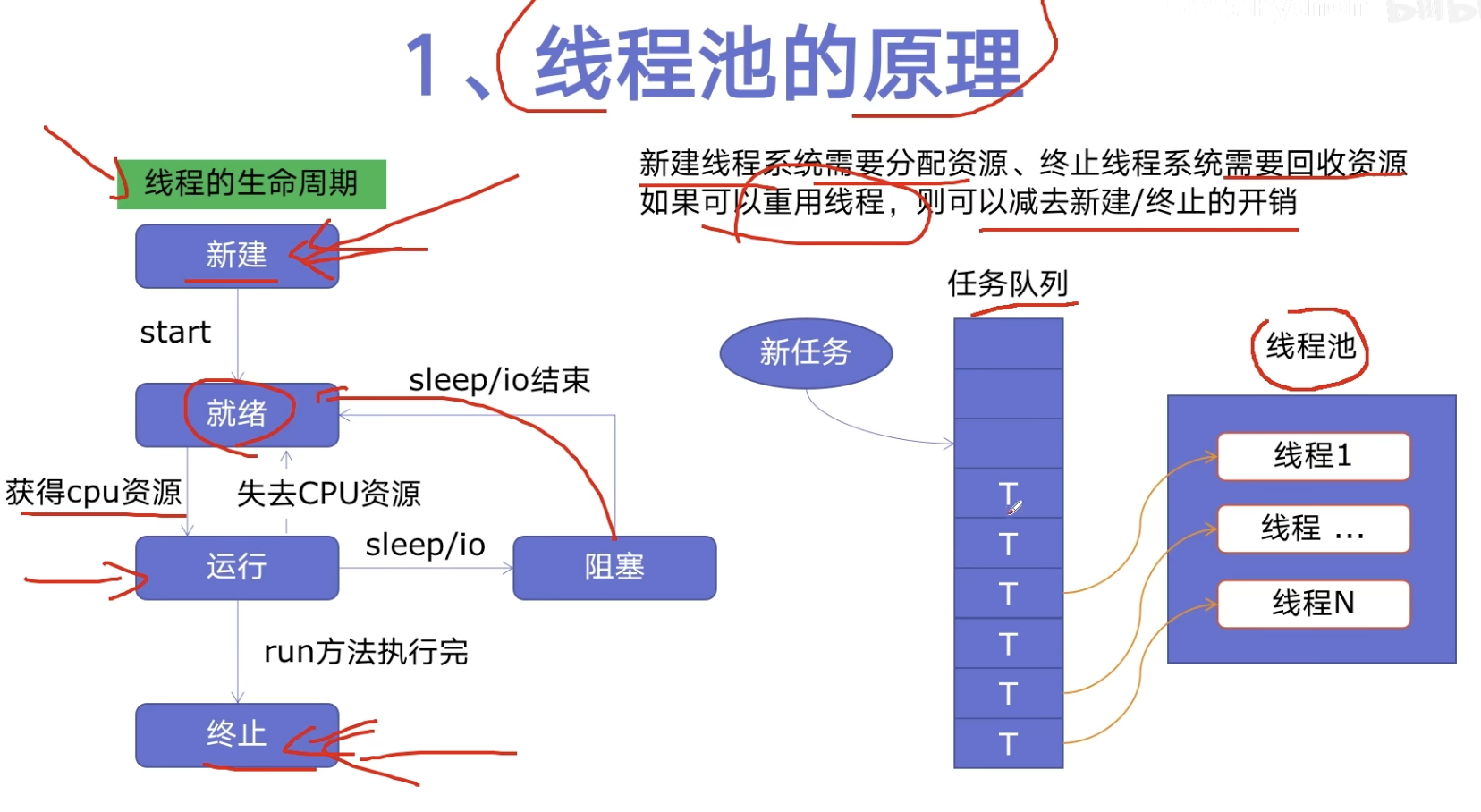
特点
- 使用任务队列
- 可重用线程
优点
- 提升性能:减少创建终止线程开销,重用线程资源
- 适用场景:突发性大量请求、但任务处理时间较短
- 防御功能:避免系统因为创建线程过多导致负荷过大
- 代码优势:简洁方便
协程的原理以及代码
【2021 最新版】Python 并发编程实战,用多线程、多进程、多协程加速程序运行_哔哩哔哩_bilibili
协程的原理
协程:在单线程内实现并发
- 核心原理:用一个超级循环(其实就是 while true)循环,配合 IO 多路复用原理(IO 时 CPU 可以干其他事情)
- 于是在等待 IO 时,CPU 会同时开始计算下一个循环的 IO 前的部分,并开启多轮循环同时进行的局面
- 等待 IO 结束,CPU 将剩余部分的代码再一并执行
单线程爬虫执行路径

协程爬虫执行路径
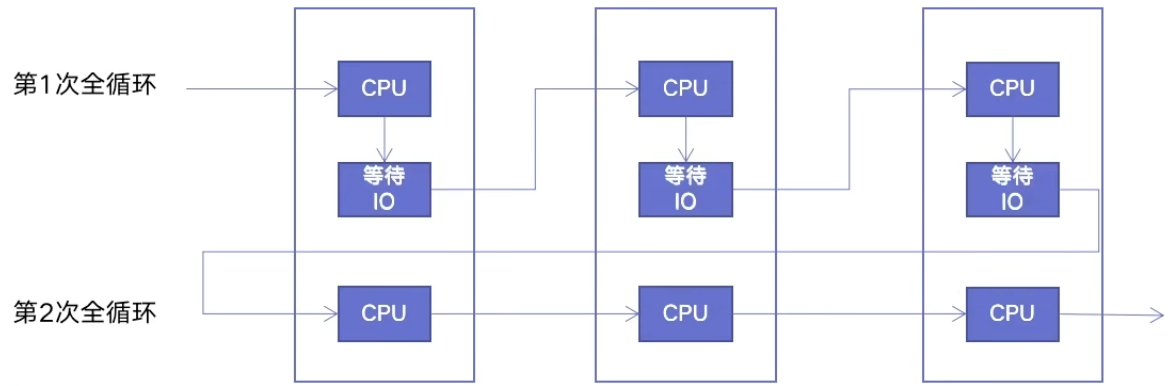
协程的使用以及异步 IO
import asyncio
# 获取事件循环(超级循环)
loop = asyncio.get_event_loop()
# 定义协程
async def myfunc(url):
await get_url(url)
# 创建task列表
tasks = [loop.create_task(myfunc(url))
for url in urls]
# 执行爬虫事件列表
loop.run_until_complete(asyncio.wait(tasks))
关键字async:表示定义一个协程。
关键字await:表示后面的函数是一个异步 IO,并且不进行阻塞,而是直接在超级循环直接进入下一个任务的执行(当前任务放弃 CPU,下一个任务获得 CPU)。
注意
异步 IO 中依赖的库必须支持异步 IO 特性(这要求库在 IO 时不能阻塞,否则切换不到下一个任务了)
注意
requests 库不支持异步 IO,需要使用 aiohttp 库
例子:
import asyncio, aiohtttp
async def async_craw(url):
async with aiohttp.ClientSession() as sess:
async with sess.get(url) as resp:
result = await resp.text()
print(url, len(result))
loop = asyncio.get_event_loop()
tasks = [loop.create_task(async_craw(url))
for url in urls]
loop.run_until_complete(asyncio.wait(tasks))
所有的异步对象也需要使用 async 关键字来标注。
相关信息
协程与普通函数运行的不同点在于协程需要使用超级循环来进行调度。
协程并发度的控制
可以使用 信号量 Semaphore 来进行控制:
import asyncio, aiohtttp
semaphore = asyncio.Semaphore(10)
async def async_craw(url):
async with semaphore: # here
async with aiohttp.ClientSession() as sess:
async with sess.get(url) as resp:
result = await resp.text()
print(url, len(result))
loop = asyncio.get_event_loop()
tasks = [loop.create_task(async_craw(url))
for url in urls]
loop.run_until_complete(asyncio.wait(tasks))
信号量 Semaphore
相关信息
信号量一般用于访问有限数量的共享资源。
信号量是一个同步对象,用于保持在 0 至指定最大值之间的一个计数器。
- 当线程完成一次对改 semaphore 对象的等待(wait)时,该计数器减一
- 当线程完成一次对改 semaphore 对象的释放(release)时,该计数器加一
- 当计数器为 0 时,线程等待该 semaphore 对象不再能成功直到该 semaphore 对象变成 signaled 状态(阻塞)
- 计数器大于 0,为 signaled 状态
- 计数器等于 0,为 nonsignaled 状态
# 方法一:使用with
sem = asyncio.Semaphore(10)
# ...later
async with sem:
# work with shared resource
# 方法二:手动acquire、release
sem = asyncio.Semaphore(10)
# ...later
await sem.acquire()
try:
# work with shared resource
finally:
sem.release()